
The Pain of Implicit Dependencies
Legacy code imposes an unbounded, inexact tax on the cost of all future features. This explains why I run events like Legacy Code Retreat, build training courses like Surviving Legacy Code, and write in general about improving the design of software systems. This further explains why I’m willing to accept the risk of people labeling me as an “over-engineerer”. What they label “over-engineering”, I consider managing risk. As part of managing risk, I like to test-drive changes to legacy code, and implicit dependencies almost always get in the way of starting. I’m going through this right now, working with Octopress, the blogging software that I use here. (Update in 2017: I have since switched from Octopress to Jekyll.)
The Task
Some time ago, gists started looking bad on this blog. I apologize for that. Gists looked (or still look, depending on when you read this) like this:
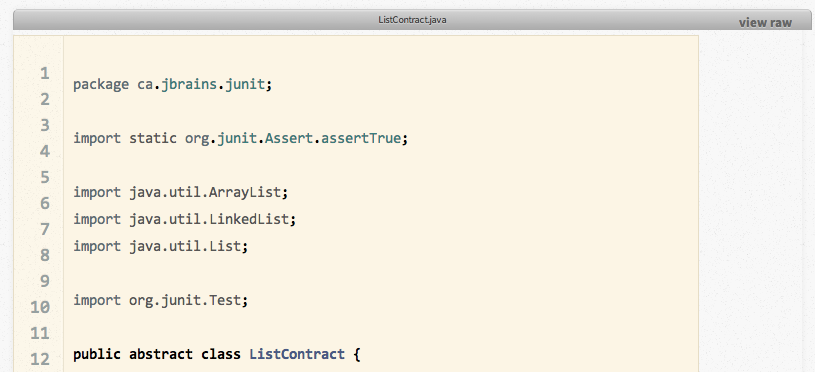
After a few hours of looking around for solutions, I decided that Github’s gist stylesheet had caused me the most misery, so I decided to sidestep it, which meant no longer embedded the gists using Javascript. This coincidentally solved some other problems, so I went with it. After some more time exploring how to do this, I settled on a simple-sounding approach: create a new Octopress tag that downloads the raw gist and displays it using the codeblock tag, which Octopress already ships.
Update 2017: Now I just use fenced code blocks in place of the codeblock Liquid tag, but the points of this article still stand.
How hard could this possibly be?
Here’s How Hard This Could Possibly Be
In order to test-drive my changes, I need to move as quickly as possible outside Octopress’s runtime environment, because otherwise my tests will forever remain big, brittle, and a ticking time bomb. I need to understand more about the contract of CodeBlock so that I can invoke it correctly from my custom Liquid::Block implementation. In the process of running some end-to-end tests—these help me discover the boundaries between “my stuff” and “their stuff”—I find what looks like a mistake in CodeBlock: when I specify only the URL for a code block (not a title nor link text), CodeBlock interprets the URL as a filename and tries to extract a file type for syntax highlighting, and so it thinks that the link’s top-level domain is the type of the code block. Oops. Naturally I want to verify that this class doesn’t intend to behave this way, and so I try writing some tests, since that will force me to think about this issue more deeply and, if I have things wrong, notice my own mistake.
Is This Thing On?
I try writing a dead-simple test that instantiates the class I want to check. I’ve learned to get this running before I try to do anything more complicated, because legacy environments often surprise me.
require "rspec"
describe "Parsing parameters for codeblock" do
example "Am I requiring everything correctly?" do
Jekyll::CodeBlock.new
end
end
Predictably, this fails with uninitialized constant Jekyll. Of course, I need to require the production code I want to check, so I do that.
require "rspec"
require "./plugins/code_block"
describe "Parsing parameters for codeblock" do
example "Am I requiring everything correctly?" do
Jekyll::CodeBlock.new
end
end
I hate the relative require path, because that encodes knowledge of where I’ve put my spec directory, and that creates context dependence. Quickly, I change the require path and when I run my specs, I run them with -I . so that ruby finds the production code.
I moved the decision up the call stack! Instead of the ruby code saying “look for require files in the current working directory”, I’ve moved that decision up to its immediate caller: the shell command that launches the ruby code. This illustrates what I meant in “Move Implementation Choices Up the Call Stack”.
Of course, I don’t want to forget this important detail, and it seems like the kind of thing I will forget easily, so I capture it in a script, which I can eventually take into a rake task.
require "rspec"
require "plugins/code_block"
describe "Parsing parameters for codeblock" do
example "Am I requiring everything correctly?" do
Jekyll::CodeBlock.new
end
end#!/bin/bash
## I don't know how better to specify "the root of this project"
PLUGIN_PRODUCTION_CODE_ROOT="."
bundle exec rspec -I $PLUGIN_PRODUCTION_CODE_ROOT spec
Now I believe that my tests require the right things, but when I run them, I see that the legacy environment has thrown me a curveball.
/Users/jbrains/Workspaces/octopress/plugins/raw.rb:22:in `<module:Jekyll>': uninitialized constant Jekyll::Liquid (NameError)
from /Users/jbrains/Workspaces/octopress/plugins/raw.rb:21:in `<top (required)>'
from /Users/jbrains/Workspaces/octopress/plugins/code_block.rb:45:in `require'
from /Users/jbrains/Workspaces/octopress/plugins/code_block.rb:45:in `<top (required)>'
from /Users/jbrains/Workspaces/octopress/spec/learn_code_block_spec.rb:2:in `require'
My tests require files correctly, but the production code does not. Yet more context dependence, because CodeBlock needs Jekyll, but doesn’t require it. Now I might simply not know about some standard ruby idiom for requiring files, but my simple, first-principles analysis of the situation tells me that files that require other files should just require those files. I suppose I would prefer it if plugins/code_block.rb could require only the small parts of Jekyll that it needs, but at a minimum, it ought not to force every client to require the parts of Jekyll that it needs. It ought not even to force clients to know which parts of Jekyll it needs. This sounds like a job for Reg’s article on defactoring.
What about injecting dependencies and moving collaborators up the call stack? Didn’t I make a big freaking deal about that recently? Why yes, I did. As Reg points out in his article, when we need flexibility we factor, and when we don’t, we defactor. When I test-drive tiny pieces of a system, I want maximum flexibility in connecting those pieces together, so I factor, which in that case involves moving collaborators up the call stack. When I package those pieces together as a ready-made system for you to use, I introduce something at the root of all my little pieces that puts them together in a cohesive manner that solves a specific problem, which you might interpret as defactoring, but which I interpret as mere politeness: giving you a bicycle, rather than an enterprise-caliber personal locomotion device toolkit. Therefore:
If your code needs something, then either provide it yourself (defactor) or make it clear to me that I need to provide it (factor explicitly). When we introduce implicit dependencies, we don’t factor, we create legacy code.
Of course, I don’t want to mess with CodeBlock yet, because I don’t understand enough about how it works, and I certainly don’t intend to tell all those Octopress plugin authors that “they’re doing it wrong”, so I require what I need along with a SMELL comment to remind me that I don’t want to have to do this.
# SMELL Production code needs Jekyll, but doesn't require it, so this file has to.
require "jekyll"
require "rspec"
require "plugins/code_block"
describe "Parsing parameters for codeblock" do
example "Am I requiring everything correctly?" do
Jekyll::CodeBlock.new
end
endAt least now, when I run my tests, I see a coding error, rather than an environment error.
Failures:
1) Parsing parameters for codeblock Am I requiring everything correctly?
Failure/Error: Jekyll::CodeBlock.new
ArgumentError:
wrong number of arguments (0 for 3)
# ./plugins/code_block.rb:54:in `initialize'
# ./spec/learn_code_block_spec.rb:9:in `new'
# ./spec/learn_code_block_spec.rb:9:in `block (2 levels) in <top (required)>'Enough Legacy Environment; Now Legacy Code
I can now start writing tests for what I truly want to check: what happens when I specify a URL, but neither a title nor link text. Although I normally start my tests with the assertion, when working with legacy code, I prefer to run the action first, because that will probably introduce more hurdles to overcome. Unsurprisingly, that happened this time, too.
# SMELL Production code needs Jekyll, but doesn't require it, so this file has to.
require "jekyll"
require "rspec"
require "plugins/code_block"
describe "Parsing parameters for codeblock" do
def code_block_with_url(url)
irrelevant_tokens = []
Jekyll::CodeBlock.new("irrelevant tag name", "https://gist.github.com/1234", irrelevant_tokens)
end
example "only a URL" do
code_block_with_url("https://gist.github.com/1234")
end
endFailures:
1) Parsing parameters for codeblock only a URL
Failure/Error: Jekyll::CodeBlock.new("irrelevant tag name", "https://gist.github.com/1234", irrelevant_tokens)
Liquid::SyntaxError:
irrelevant tag name tag was never closed
# ./plugins/code_block.rb:73:in `initialize'
# ./spec/learn_code_block_spec.rb:10:in `new'
# ./spec/learn_code_block_spec.rb:10:in `code_block_with_url'
# ./spec/learn_code_block_spec.rb:14:in `block (2 levels) in <top (required)>'
I don’t care about closing tags; I only care about parsing text. Yet more context dependence. In this case, CodeBlock’s constructor invokes super, which invokes the Liquid framework. This defeats the purpose of a framework. This particular example typifies two problems: a framework extension point invoking the framework directly and inheriting implementation. I prefer not to do either.
Framework invokes you; you invoke libraries. Never invoke a framework directly.
Inheriting implementation (subclassing) hardwires you to depend on potentially untested and untrusted code, so inherit interface (protocol) instead.
How do I escape the annoying context of Liquid with minimal change to the production code? I use a trick that I teach in Surviving Legacy Code: I extract a pure function that parses the parameters. I have to do this carefully, because I don’t have tests to shield me from my own mistakes. I hate doing this kind of surgery, but I can’t think of a better way to do this. I perform these steps:
- Copy the parsing code to a new function. (Never cut; always copy, then fix, then delete.)
- Add the input parameters that the function needs.
-
Return a
Hashcontaining the values of the fields that the function sets. - Change the fields to local variables.
This last step stops the function from writing to its surrounding context, but the function still reads from its surrounding context: it uses two constants. I won’t let that stop me from my next step, but I do need to remember to fix that.
module Jekyll
class CodeBlock < Liquid::Block
include HighlightCode
include TemplateWrapper
CaptionUrlTitle = /(\S[\S\s]*)\s+(https?:\/\/\S+|\/\S+)\s*(.+)?/i
Caption = /(\S[\S\s]*)/
def initialize(tag_name, markup, tokens)
@title = nil
@caption = nil
@filetype = nil
@highlight = true
# BEGIN EXTRACTING HERE
if markup =~ /\s*lang:(\S+)/i
@filetype = $1
markup = markup.sub(/\s*lang:(\S+)/i,'')
end
if markup =~ CaptionUrlTitle
@file = $1
@caption = "<figcaption><span>#{$1}</span><a href='#{$2}'>#{$3 || 'link'}</a></figcaption>"
elsif markup =~ Caption
@file = $1
@caption = "<figcaption><span>#{$1}</span></figcaption>\n"
end
if @file =~ /\S[\S\s]*\w+\.(\w+)/ && @filetype.nil?
@filetype = $1
end
# END EXTRACTING HERE
super
end
end
end
I extracted parse_tag_parameters, which turns markup into the set of fields that the previous code wrote to.
module Jekyll
class CodeBlock < Liquid::CodeBlock
# unimportant stuff elided
def self.parse_tag_parameters(markup)
if markup =~ /\s*lang:(\S+)/i
filetype = $1
markup = markup.sub(/\s*lang:(\S+)/i,'')
end
if markup =~ CaptionUrlTitle
file = $1
caption = "<figcaption><span>#{$1}</span><a href='#{$2}'>#{$3 || 'link'}</a></figcaption>"
elsif markup =~ Caption
file = $1
caption = "<figcaption><span>#{$1}</span></figcaption>\n"
end
if file =~ /\S[\S\s]*\w+\.(\w+)/ && filetype.nil?
filetype = $1
end
return {filetype: filetype, file: file, caption: caption}
end
end
endI have not yet changed the constructor to use this newly-extracted function out of a desire to do this safely.
Now, at least, I can greatly simplify the test.
# SMELL Production code needs Jekyll, but doesn't require it, so this file has to.
require "jekyll"
require "rspec"
require "plugins/code_block"
describe "Parsing parameters for codeblock" do
example "only a URL" do
Jekyll::CodeBlock.parse_tag_parameters("https://gist.github.com/1234")
end
endI can even run this test and it does nothing. With legacy code, this represents progress.
How about we check something now?
Now to the actual mistake—or at least what seems like a mistake. When I don’t provide any clue about the “type” of the code snippet—whether to interpret it as Java code, Ruby code, or something else—then perhaps the filetype should be nil. At a minimum, it shouldn’t be what it is now.
describe "Parsing parameters for codeblock" do
example "only a URL" do
results = Jekyll::CodeBlock.parse_tag_parameters("https://gist.github.com/1234")
results[:filetype].should be_nil
end
end 1) Parsing parameters for codeblock only a URL
Failure/Error: results[:filetype].should be_nil
expected: nil
got: "com"
# ./spec/learn_code_block_spec.rb:10:in 'block (2 levels) in <top (required)>'My code snippet certainly doesn’t contain code of type “com”, whatever that means, so I interpret this as a mistake and change my test accordingly.
describe "Parsing parameters for codeblock" do
example "only a URL" do
results = Jekyll::CodeBlock.parse_tag_parameters("https://gist.github.com/1234")
pending("Filetype appears to be interpreted incorrectly") do
results[:filetype].should be_nil
end
end
end
Now I should remove the duplication in CodeBlock to avoid future mistakes. This involves wiring its constructor, very carefully to the code I’ve just extracted.
module Jekyll
class CodeBlock < Liquid::Block
def initialize(tag_name, markup, tokens)
@title = nil
@caption = nil
@filetype = nil
@highlight = true
parsed_tag_parameters = self.class.parse_tag_parameters(markup)
@filetype = parsed_tag_parameters[:filetype]
@file = parsed_tag_parameters[:file]
@caption = parsed_tag_parameters[:caption]
super
end
end
endSome rudimentary manual checking convinced me that this change hasn’t broken anything. With legacy code, sometimes we can’t do any better than that, which explains why I go to such pains to avoid writing more of it.
Of course, now I see some silly-looking duplication in the constructor, so I remove it. I also see some possibly-obsolete code, so I mark it as such. I’ll need to explore more whether I can safely delete that code.
module Jekyll
class CodeBlock < Liquid::Block
def initialize(tag_name, markup, tokens)
# SMELL This appears to be completely unused.
@title = nil
@highlight = true
parsed_tag_parameters = self.class.parse_tag_parameters(markup)
@filetype = parsed_tag_parameters[:filetype]
# SMELL This appears to be completely unused.
@file = parsed_tag_parameters[:file]
@caption = parsed_tag_parameters[:caption]
super
end
end
endWhat now?
Now I can explore more fully and more safely the behavior of parsing the CodeBlock’s tag parameters, and I won’t bore you with the details. I can do all this with tests that depend only on the existence of the module Jekyll, but on none of its behavior. Not perfect, but much better. I don’t yet need to factor out the parse_tag_parameters() behavior any more, but I feel much more comfortable doing that when the time comes, because I know it will cost me much less than it cost me to get to this point.
The lesson?
Don’t depend on your clients. If you have to depend on your clients, depend on as little as possible, and remove that dependency as soon as you can.
All legacy code started with “I’ll just cut this little corner, and it won’t be so bad….”
An annoying epilogue
By the way, in the process of exploring how to contribute these changes back to Octopress, I discovered that a new major release is coming and everything will have changed. No good deed goes unpunished.
A less-annyoing epiepilogue
I switched from Octopress to Jekyll. Since Octopress was moving in the direction of “a bunch of plugins for Jekyll”, this move was likely to happen.
Comments